
Ejercicios Lección 7
Ejercicios de lo aprendido en la lección 7 expresiones regulares
NUMB3RS
En la temporada 5, episodio 23 de NUMB3RS , aparece en pantalla una supuesta dirección IP275.3.6.28 , que en realidad no es una dirección IPv4 (o IPv6 ) válida.
Una dirección IPv4 es un identificador numérico que un dispositivo (o, en la televisión, un hacker) utiliza para comunicarse en Internet, similar a una dirección postal en el mundo real, normalmente formateado en notación decimal con puntos como #.#.#.#. Pero cada uno #debería ser un número entre 0y 255, inclusive. ¡Basta decir 275que no está en ese rango! ¡Si tan solo NUMB3RS hubiera validado la dirección en esa escena!
En un archivo llamado numb3rs.py, implemente una función llamada validateque espera una dirección IPv4 como entrada como a stry luego devuelve Trueo False, respectivamente, si esa entrada es una dirección IPv4 válida o no.
La estructura numb3rs.pyes la siguiente, donde puede modificar mainy/o implementar otras funciones como mejor le parezca, pero no puede importar ninguna otra biblioteca. Eres bienvenido, pero no obligado, a utilizar rey/o sys.
import re
import sys
def main():
print(validate(input("IPv4 Address: ")))
def validate(ip):
...
...py
if __name__ == "__main__":
main()
Ya sea antes o después de implementar validateen numb3rs.py, implemente adicionalmente, en un archivo llamado test_numb3rs.py, dos o más funciones que en conjunto prueban su implementación validatea fondo, cada uno de cuyos nombres debe comenzar con test_para que pueda ejecutar sus pruebas con:
pytest test_numb3rs.py
Consejos
- Recuerde que el
remódulo viene con bastantes funciones, según docs.python.org/3/library/re.html , incluidassearch. - Recuerde que las expresiones regulares admiten bastantes caracteres especiales, según docs.python.org/3/library/re.html#regular-expression-syntax .
- Debido a que las barras invertidas en las expresiones regulares pueden confundirse con secuencias de escape (como
\n), es mejor usar la notación de cadenas sin formato de Python para los patrones de expresiones regulares ; de lo contrario,pytestse advertirá conDeprecationWarning: invalid escape sequence. Así como las cadenas de formato tienen el prefijof, también las cadenas sin formato tienen el prefijor. Por ejemplo, en lugar de"harvard\.edu", utilicer"harvard\.edu". - Tenga en cuenta que
re.search, si se le pasa un patrón con "grupos de captura" (es decir, paréntesis), devuelve un "objeto de coincidencia", según docs.python.org/3/library/re.html#match-objects , donde las coincidencias están indexadas en 1 , al que puede acceder individualmente congroup, según docs.python.org/3/library/re.html#re.Match.group , o colectivamente congroups, según docs.python.org/3/library/re.html#re. Grupos de partidos .
Ver en YouTube
Resulta que (la mayoría) de los vídeos de YouTube se pueden incrustar en otros sitios web, como el anterior. Por ejemplo, si visita https://youtu.be/@bunkerdevs en una computadora portátil o de escritorio, hace clic en Compartir y luego en Insertar , verá HTML (el idioma en el que se escriben las páginas web) como el siguiente, que Luego podría copiarlo en el código fuente de su propio sitio web, donde iframehay un "elemento" HTML y srces uno de varios "atributos" HTML que contiene, cuyo valor, entre comillas, es https://youtu.be/o-vQG56AJw8?si=A9n00FSsmQjPt2bQ.
<iframe width="560" height="315" src="https://www.youtube.com/embed/o-vQG56AJw8?si=A9n00FSsmQjPt2bQ" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
Debido a que algunos atributos HTML son opcionales, podrías incrustar mínimamente solo lo siguiente.
<iframe src="https://youtu.be/embed/o-vQG56AJw8?si=A9n00FSsmQjPt2bQ"></iframe>
Supongamos que desea extraer las URL de los vídeos de YouTube que están incrustados en páginas (por ejemplo, https://www.youtube.com/embed/o-vQG56AJw8?si=A9n00FSsmQjPt2bQ), convirtiéndolas nuevamente en youtu.beURL más cortas y compartibles (por ejemplo, https://youtu.be/o-vQG56AJw8?si=A9n00FSsmQjPt2bQ) donde se pueden ver en el propio YouTube.
En un archivo llamado watch.py, implemente una función llamada parseque espera un strHTML como entrada, extrae cualquier URL de YouTube que sea el valor de un srcatributo de un iframeelemento allí y devuelve su youtu.beequivalente más corto y compartible como un str. Espere que dicha URL esté en uno de los formatos siguientes. Supongamos que el valor de srcestará entre comillas dobles. Y supongamos que la entrada no contendrá más de una de esas URL. Si la entrada no contiene ninguna URL de este tipo, devuelva None.
http://youtube.com/embed/o-vQG56AJw8?si=A9n00FSsmQjPt2bQhttps://youtube.com/embed/o-vQG56AJw8?si=A9n00FSsmQjPt2bQhttps://www.youtube.com/embed/o-vQG56AJw8?si=A9n00FSsmQjPt2bQ
La estructura watch.pyes la siguiente, donde puede modificar mainy/o implementar otras funciones como mejor le parezca, pero no puede importar ninguna otra biblioteca. Eres bienvenido, pero no obligado, a utilizar rey/o sys.
import re
import sys
def main():
print(parse(input("HTML: ")))
def parse(s):
...
...
if __name__ == "__main__":
main()
Consejos
- Recuerde que el
remódulo viene con bastantes funciones, según docs.python.org/3/library/re.html , incluidassearch. - Recuerde que las expresiones regulares admiten bastantes caracteres especiales, según docs.python.org/3/library/re.html#regular-expression-syntax .
- Debido a que las barras invertidas en las expresiones regulares pueden confundirse con secuencias de escape (como
\n), es mejor utilizar la notación de cadenas sin formato de Python para los patrones de expresiones regulares . Así como las cadenas de formato tienen el prefijof, también las cadenas sin formato tienen el prefijor. Por ejemplo, en lugar de"harvard\.edu", utilicer"harvard\.edu". - Tenga en cuenta que
re.search, si se le pasa un patrón con "grupos de captura" (es decir, paréntesis), devuelve un "objeto de coincidencia", según docs.python.org/3/library/re.html#match-objects , donde las coincidencias están indexadas en 1 , al que puede acceder individualmente congroup, según docs.python.org/3/library/re.html#re.Match.group , o colectivamente congroups, según docs.python.org/3/library/re.html#re. Grupos de partidos . - Tenga en cuenta que
*y+son "codiciosos", en la medida en que "coinciden con la mayor cantidad de texto posible", según docs.python.org/3/library/re.html#regular-expression-syntax . Agregar?inmediatamente después, a la*?o+?, “hace que realice el partido de manera mínima o no codiciosa; Se emparejarán la menor cantidad de personajes posible”.
Trabajando de 9 a 5
Mientras que la mayoría de los países utilizan un reloj de 24 horas , Estados Unidos tiende a utilizar un reloj de 12 horas . En consecuencia, en lugar de “09:00 a 17:00”, muchos estadounidenses dirían que trabajan “de 9:00 a. m. a 5:00 p. m.” (o “de 9 a. m. a 5 p. m.”), donde “AM” es una abreviatura de “ante meridiem” y “PM” es una abreviatura de “post meridiem”, donde “meridiem” significa mediodía (es decir, mediodía).
Tabla de conversión
En un archivo llamado working.py, implemente una función llamada convertque espera a stren cualquiera de los formatos de 12 horas siguientes y devuelve el correspondiente stren formato de 24 horas (es decir, 9:00 to 17:00). Espere que AMy PMesté en mayúscula (sin puntos) y que haya un espacio antes de cada uno. Supongamos que estos horarios son representativos de los horarios reales, no necesariamente las 9:00 a. m. y las 5:00 p. m. específicamente.
9:00 AM to 5:00 PM9 AM to 5 PM
En su lugar , genere a ValueErrorsi la entrada convertno está en ninguno de esos formatos o si alguna de las horas no es válida (p. ej. 12:60 AM, 13:00 PM, etc.). Pero no asuma que las horas de alguien comenzarán ante meridiem y terminarán post meridiem; alguien podría trabajar hasta tarde e incluso muchas horas (p. ej., 5:00 PM to 9:00 AM).
La estructura working.pyes la siguiente, donde puede modificar mainy/o implementar otras funciones como mejor le parezca, pero no puede importar ninguna otra biblioteca. Eres bienvenido, pero no obligado, a utilizar rey/o sys.
import re
import sys
def main():
print(convert(input("Hours: ")))
def convert(s):
...
...
if __name__ == "__main__":
main()
Ya sea antes o después de implementar converten working.py, implemente adicionalmente, en un archivo llamado test_working.py, tres o más funciones que en conjunto prueban su implementación converta fondo, cada uno de cuyos nombres debe comenzar con test_para que pueda ejecutar sus pruebas con:
pytest test_working.py
Consejos
Recuerde que el
remódulo viene con bastantes funciones, según docs.python.org/3/library/re.html , incluidassearch.Recuerde que las expresiones regulares admiten bastantes caracteres especiales, según docs.python.org/3/library/re.html#regular-expression-syntax .
Debido a que las barras invertidas en las expresiones regulares pueden confundirse con secuencias de escape (como
\n), es mejor usar la notación de cadenas sin formato de Python para los patrones de expresiones regulares ; de lo contrario,pytestse advertirá conDeprecationWarning: invalid escape sequence. Así como las cadenas de formato tienen el prefijof, también las cadenas sin formato tienen el prefijor. Por ejemplo, en lugar de"harvard\.edu", utilicer"harvard\.edu".Tenga en cuenta que
re.search, si se le pasa un patrón con "grupos de captura" (es decir, paréntesis), devuelve un "objeto de coincidencia", según docs.python.org/3/library/re.html#match-objects , donde las coincidencias están indexadas en 1 , al que puede acceder individualmente congroup, según docs.python.org/3/library/re.html#re.Match.group , o colectivamente congroups, según docs.python.org/3/library/re.html#re. Grupos de partidos .Tenga en cuenta que puede formatear un
intcon ceros a la izquierda con código comoprint(f"{n:02}")donde, si
nes un solo dígito, tendrá el prefijo uno0, según docs.python.org/3/library/string.html#format-string-syntax .
Expresiones regulares, um.
No es raro, al menos en inglés, decir “um” cuando se intenta pensar en una palabra. Sin embargo, cuanto más lo haces, ¡más notorio tiende a ser!
En un archivo llamado um.py, implemente una función llamada countque espera una línea de texto como entrada como a stry devuelve, como an int, el número de veces que "um" aparece en ese texto, sin distinguir entre mayúsculas y minúsculas, como una palabra en sí misma, no como una subcadena de alguna otra palabra. Por ejemplo, dado un texto como hello, um, world, la función debería devolver 1. Sin embargo, dado un texto como yummy, la función debería devolver 0.
La estructura um.pyes la siguiente, donde puede modificar mainy/o implementar otras funciones como mejor le parezca, pero no puede importar ninguna otra biblioteca. Eres bienvenido, pero no obligado, a utilizar rey/o sys.
import re
import sys
def main():
print(count(input("Text: ")))
def count(s):
...
...
if __name__ == "__main__":
main()
Ya sea antes o después de implementar counten um.py, implemente adicionalmente, en un archivo llamado test_um.py, tres o más funciones que en conjunto prueban su implementación counta fondo, cada uno de cuyos nombres debe comenzar con test_para que pueda ejecutar sus pruebas con:
pytest test_um.py
Consejos
- Recuerde que el
remódulo viene con bastantes funciones, según docs.python.org/3/library/re.html , incluidasfindall. - Recuerde que las expresiones regulares admiten bastantes caracteres especiales, según docs.python.org/3/library/re.html#regular-expression-syntax .
- Debido a que las barras invertidas en las expresiones regulares pueden confundirse con secuencias de escape (como
\n), es mejor utilizar la notación de cadenas sin formato de Python para los patrones de expresiones regulares . Así como las cadenas de formato tienen el prefijof, también las cadenas sin formato tienen el prefijor. Por ejemplo, en lugar de"harvard\.edu", utilicer"harvard\.edu". - Tenga en cuenta que
\bestá "definido como el límite entre a\wy un\Wcarácter (o viceversa), o entre\wel principio y el final de la cadena", según docs.python.org/3/library/re.html#regular-expression- sintaxis . - Puede que regex101.com o regexr.com le resulten útiles para probar expresiones regulares (y visualizar coincidencias).
- Consulte thefreedictionary.com/words-containing-um para ver algunas palabras que contienen "um".
Validación de respuesta
Al crear un formulario de Google que solicita a los usuarios una respuesta breve (o un párrafo), es posible habilitar la validación de respuestas y exigir que la entrada del usuario coincida con una expresión regular . Por ejemplo, podría solicitar que un usuario ingrese una dirección de correo electrónico con una expresión regular como esta :
^[a-zA-Z0-9.!#$%&'*+\/=?^_`{|}~-]+@[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(?:\.[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*$
O podría utilizar más fácilmente el soporte integrado de Google para validar una dirección de correo electrónico, según la captura de pantalla siguiente, de forma muy similar a como podría utilizar una biblioteca en su propio código:
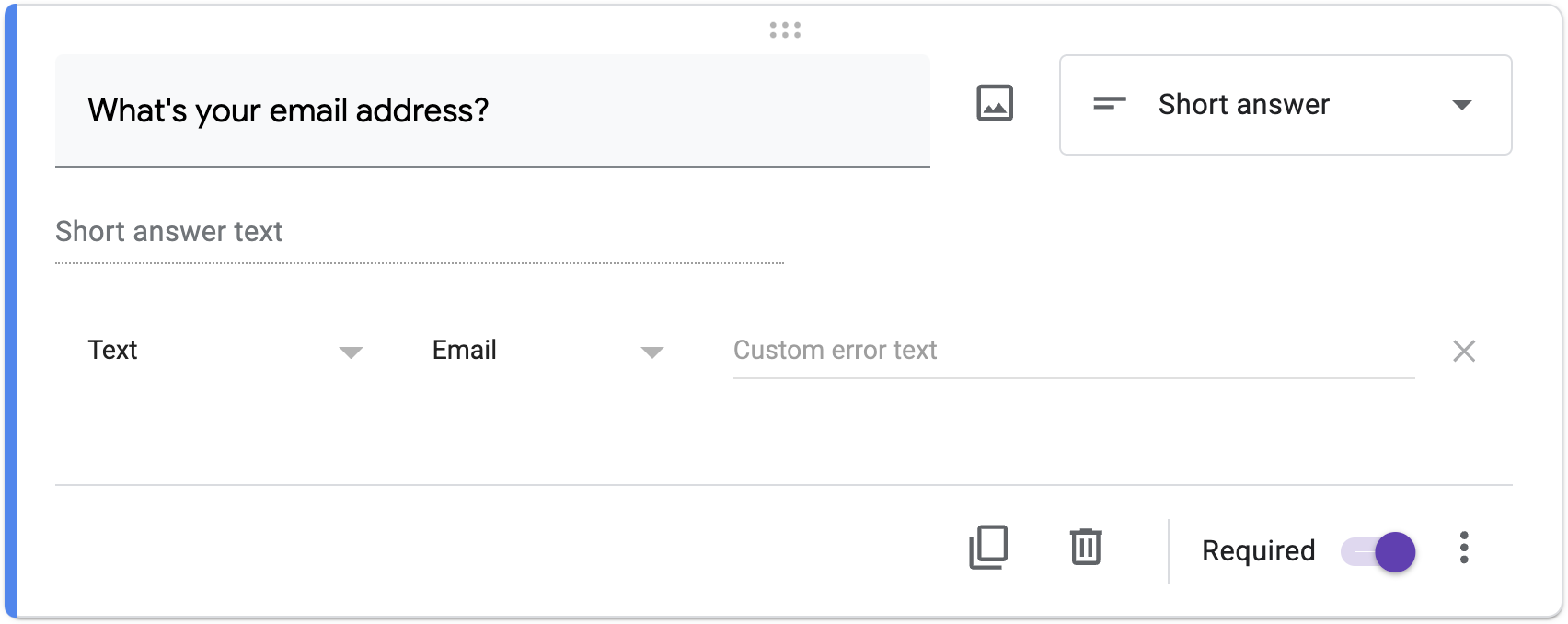
En un archivo llamado response.py, utilizando validator-collection o validadores de PyPI, implemente un programa que solicite al usuario una dirección de correo electrónico inputy luego imprima Valido Invalid, respectivamente, si la entrada es una dirección de correo electrónico sintácticamente válida. No puedes usar re. Y no valide si el nombre de dominio de la dirección de correo electrónico realmente existe.
Consejos
Tenga en cuenta que puede instalar validator-collection con:
pip install validator-collectionHaga clic en Página de inicio para encontrar la documentación de la biblioteca.
Tenga en cuenta que puede instalar validadores con:
pip install validatorsHaga clic en Página de inicio para encontrar la documentación de la biblioteca.